Jinkela(金坷垃)Pipeline 华宇注册是一套用于前端 DevOps 的实验性的胶水工具,解决了许多开发流程中的细节问题,希望简化前端发布的操作难度,如今能力被集成到 Dejavu(逮虾户) 这个在线平台,承载上百个前端业务仓库的 CI/CD 能力。
本次分享我想尽可能帮助你:
动机
不合理流程设计带来的潜在危害

不合理的流程设计,会导致开发者心惊胆战,即便今后改善了流程设计,一朝被蛇咬十年怕井绳,看不见的影响依然会在开发者之间传递。
以一个前端项目简化的发布流程为例,假设我们想实现一套文件部署成功后生效配置文件的逻辑,该如何做呢?
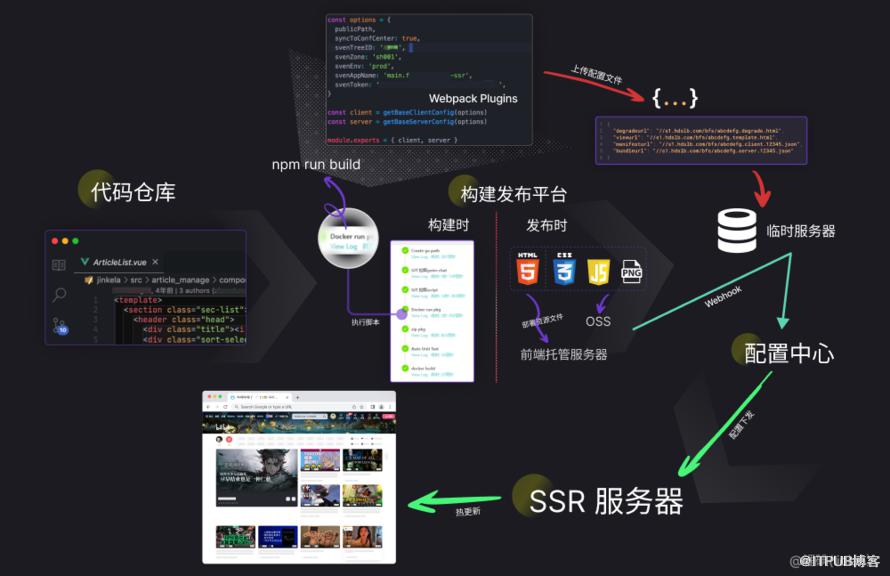
由于 过去的某个构建发布平台 定制化能力很差,无法原生地 在任意执行阶段 实现流程自动化,只能在本不该执行的时机 辅之以 臃肿的 插件/临时服务器/Webhook…… 显然,这会造成相当大的发布隐患。
此外,部分项目还要在线上平台发布完成后,回到开发机本地环境下,执行本地 CLI 来上传资源,自动化程度很低。
每次发布的感受,像是操作一台复杂的难以记忆的机器。出了事故 也只能在原有的基础上缝缝补补。
这样的现状导致自动化的最佳实践很难被沉淀下来,单一团队很难有魄力釜底抽薪地解决问题。
我们需要更多生命周期自定义钩子,便于集成各种前端特有基建,实现自动化。
前端特有业务流程的自动化
现如今 “前端”可以涉猎的职能越来越多,因不同业务的需要,逐渐分化出了不同的技术选型,我们在研发过程中会接触到各种类型的项目。
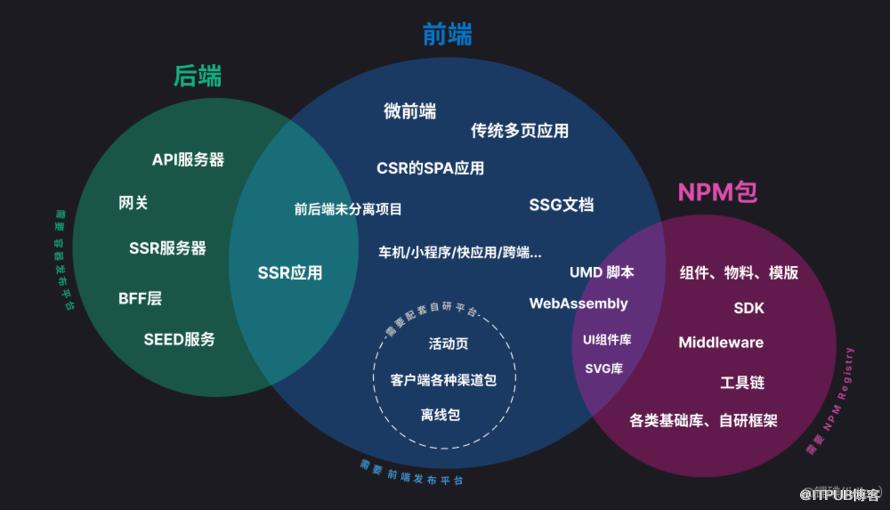
过去少数项目即可打华宇注册 造出的一个完整项目,现在往往需要多种技术栈 几十个项目 相互配合以达成。
一方面原因是外部用户需求变得更加复杂,一方面也因为 前端模块化、工程化 在发展。对代码的复用、抽象 都提出了挑战,我们更加关注「同一份代码被更多地方复用」,自然而然会让项目基数变得庞大。
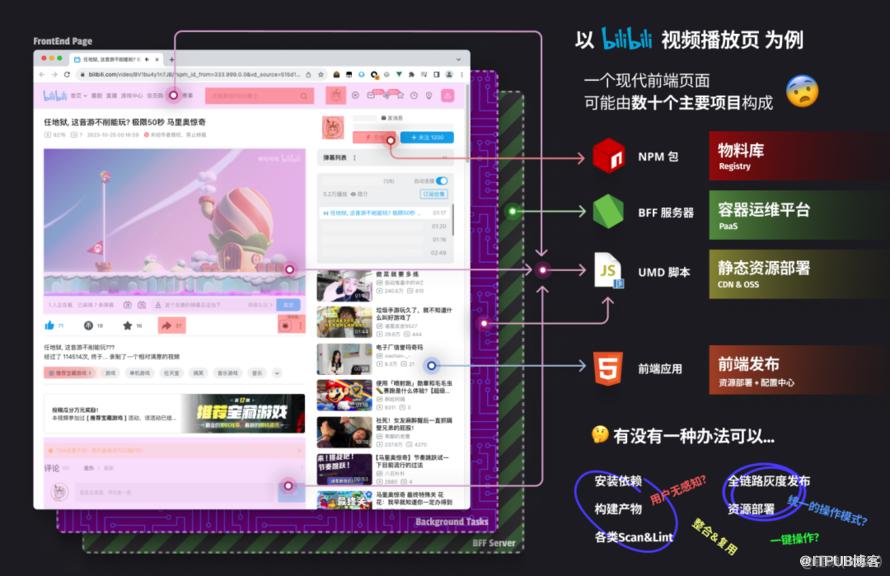
一个现代的前端页面,往往不局限于单一的部署目的地,更可能是多种部署方式的排列组合。
开发流程又是为了最终部署场景服务的,所以开发流程会变得千奇百怪。
当这些开发流程相互交织、膨胀到一定程度时,开发者就会倍感吃力,此时我们就要思考如何化繁为简了。

减少机械性的冗余操作
我们开发过程中是否会遇到一些冗余的操作步骤?
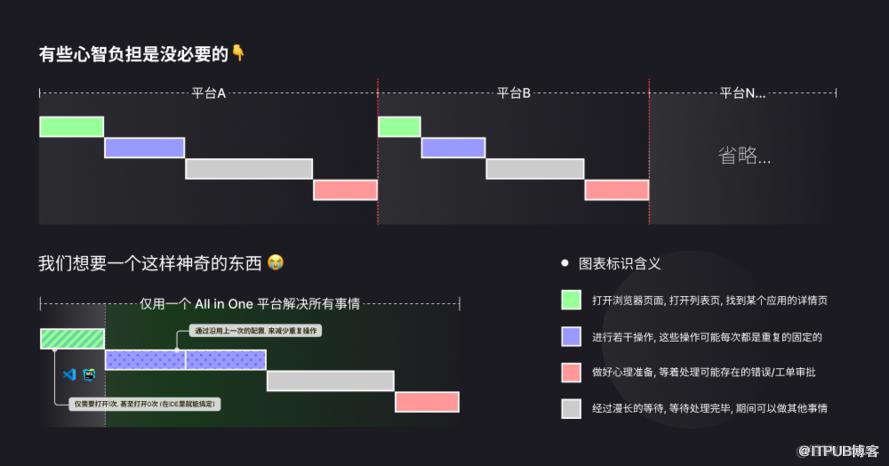
我们想要一个更简单的东西
排查问题不便
这么多工具中,我们经常会发现有重合的功能点,比如,标签(Tag)和版本号(Version) 类似的元信息功能 几乎无处不在,目的是便于我们快速找到相应的资源。
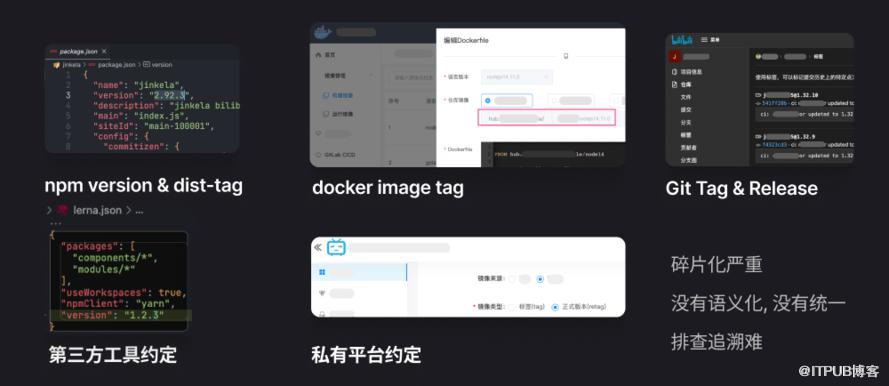
当自动化程度比较低、各工具隔阂尚未打通时,由于操作困难,版本号/Tag 功能会变得形同虚设,多个平台之间 用户倾向于随意标记 导致版本号对不上号,失去了其便于溯源的作用。
长此以往,「版本号/Tag 变得不再可信」的认知会根深蒂固,大家更信任同样在各个工具中出现的另一个稳定的东西――Commit Sha。
然而 Commit Sha 这串随机字符串还是太不直观了,我们需要重新让这些碎片化的 版本号/Tag 变得再度语义化、可被利用。
前端发布流程相对简单
在我们谈起「前端发布流程」的时候,我们常常想起的是 每天高频次的发版次数、被数十个前端项目支配的恐惧、前往各种平台处理琐碎事务、各种繁杂的前端工程化工具,有种 严肃、混沌、不明觉厉 的感觉。
那不妨让我们回忆一下 从十几年前到现在 前端是如何部署的,淡化这种恐惧。
前端部署的最简流程是什么?
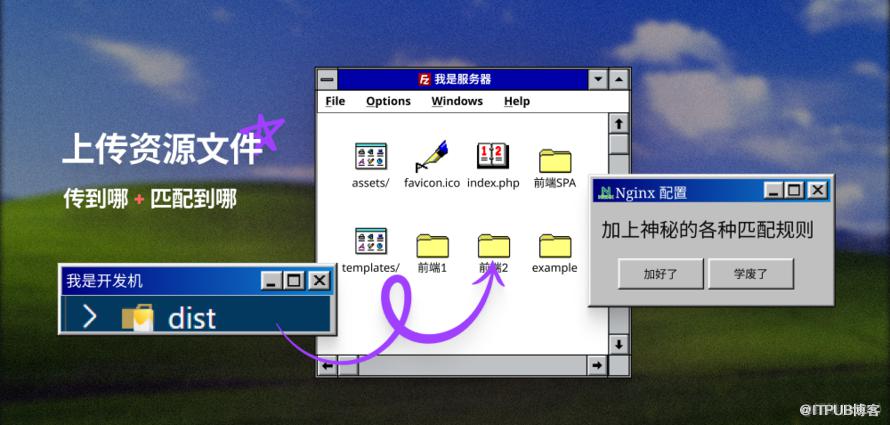
在很久以前,作为超文本标记语言的开发者,我们只需要.……
啊,这就完事儿了,已经可以顺利从浏览器访问到网页了。??
再高级点?在部署前做些什么?
想想看,IE 浏览器尚存时、新兴浏览器的用户又想要获得更好的体验,我们希望兼容各种浏览器、简化代码维护成本,就会引入一些小工具……
举例 因浏览器的特性 所以才会做的力所能及的优化
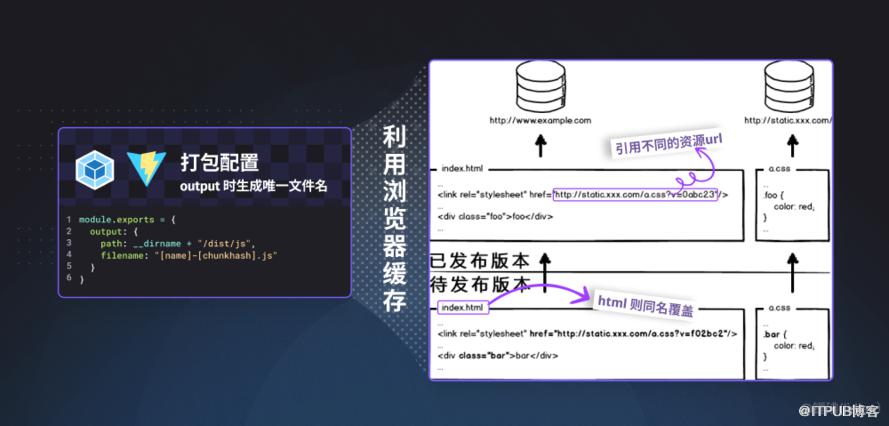
改写一下 webpack gulp 等打包器 “编译时” 的配置,让文件名携带唯一标识符,便于配合浏览器的缓存机制。
如果恰好还用了什么 CDN,还可以给不同 bucket 设置不同的访问特性,
打包出不同类型不同分块的内容,把它们各自传到适合的地方。
举例 本机开发时 借助工具 实现一定程度的半自动化
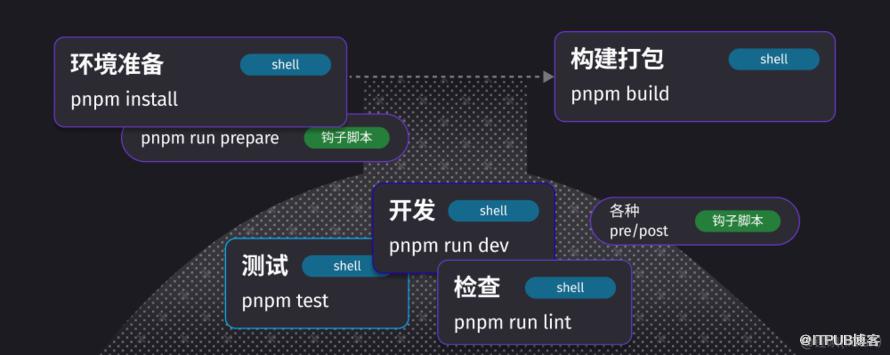
使用 npm scripts (类似 Makefile) 结合各种工具 来实现本地开发时的半自动化
举例 因不同用途 分离出不同的开发环境

前端生态工具链中 实际利用好”环境变量” 这一古早概念 已经特别晚了。
为了分离出“测试-预发-生产”环境 (即 同一套代码打出不同产物包),需要 if-else 判断 process.env.环境变量,来实现构建过程中的多态性。
PS: 直到 2023年 dotenv 才被主流运行时 都原生支持,在这之前可以看到大量的项目都在使用各种千奇百怪的方式 读取 环境变量
PS: 包管理器本体或插件 也可以支持 读取 dotenv 文件
例如,这是某个仓库下的情况……
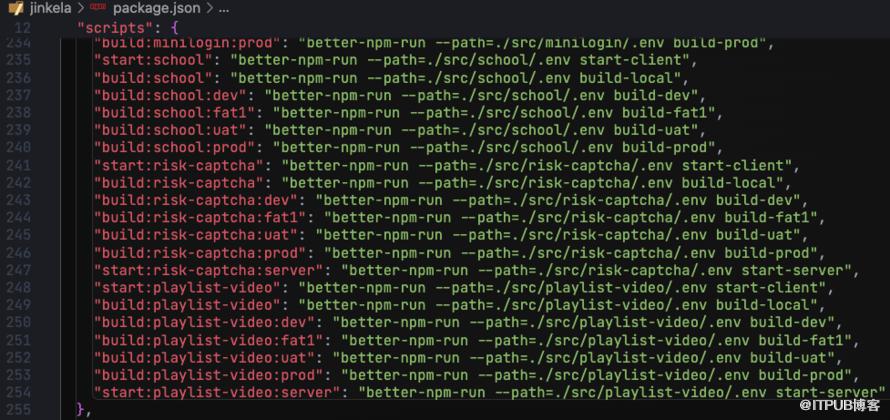
再再高级点?拥有一个平台
前后端分离的开发模式深入人心后,前端也需要专有的平台,满足局部发布、动态化可配置 等需求。
其实不管是过去还是现在,大多数的前端应用的部署过程,都是上述几个例子的排列组合。
万变不离其宗 ―― 本质就是花式“处理静态资源文件”。
我们需要一种返璞归真的方法,把繁杂概念的溶解在简易的操作模式背后。
雏形中的解决方案
此时,主站前端已经有一些解决方案在探索中了。
例如,有同学根据构建发布平台提供的 OpenAPI,开发了 CLI 小工具,用脚本代替手动操作。

它可以支持 一次性触发多个项目的构建,例如 顶导 被数十个前端项目引用,改一次需要同步修改其他项目的话,这数十个前端项目可以第一时间同时构建。
需要用户在仓库根目录 显性地配置 一张包含「子应用――平台应用配置」的配置表,维护起来很麻烦。但只需配置一次,其他人在使用时 并不会感知到配置流程。
CI/CD 实现
使用体验
Jinkela Pipeline 将各种操作流程都封装为统一风格的命令行交互逻辑,适度屏蔽了用户感知,把繁杂的操作都化简为一次次键盘回车事件。
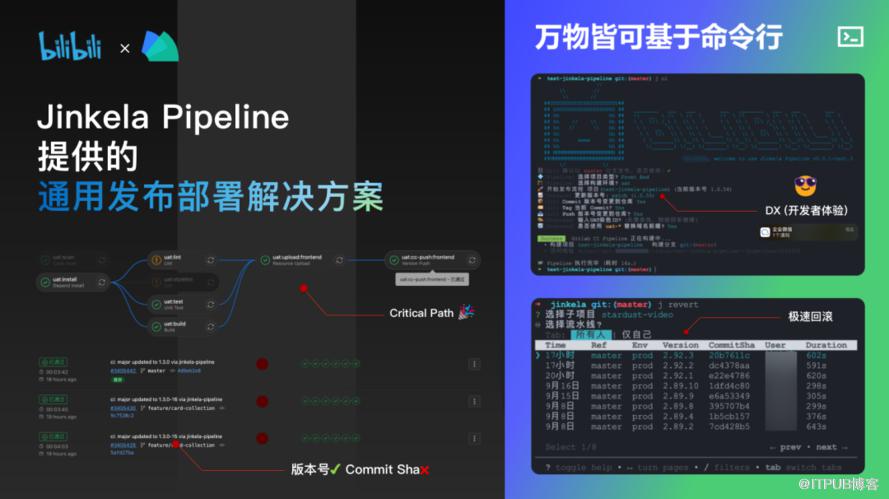
简易的架构实现
如果想搭建一套简单的 DevOps 工具链,按下图所示的分层架构,我们可以根据需要敏捷地开发任意部分,今后也可以复杂化任意部分。

再简化点就是,「条件」 + 「执行」,是不是发现身边有很多这样类似的工具?
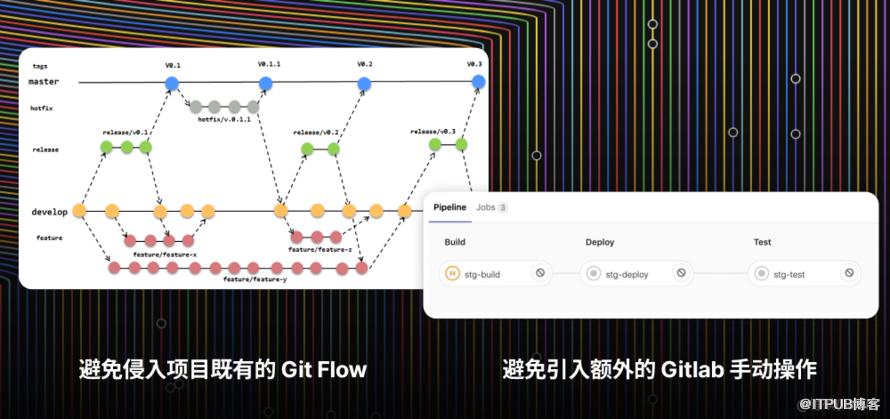
核心就是 仅利用 Gitlab CI 提供的「Pipeline 创建API」作为衔接整条链路的桥梁,允许我们把具有副作用的、需要手动完成的流程前置,把自动化执行的部分后置。
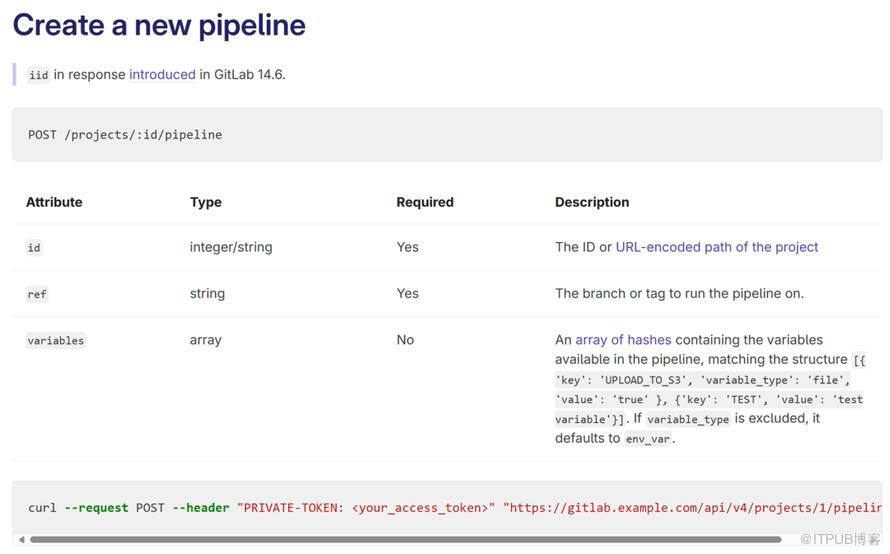
基于关注点分离原则,分为三层,每一层解决的问题截然不同。
交互,提供 构建参数 + 环境变量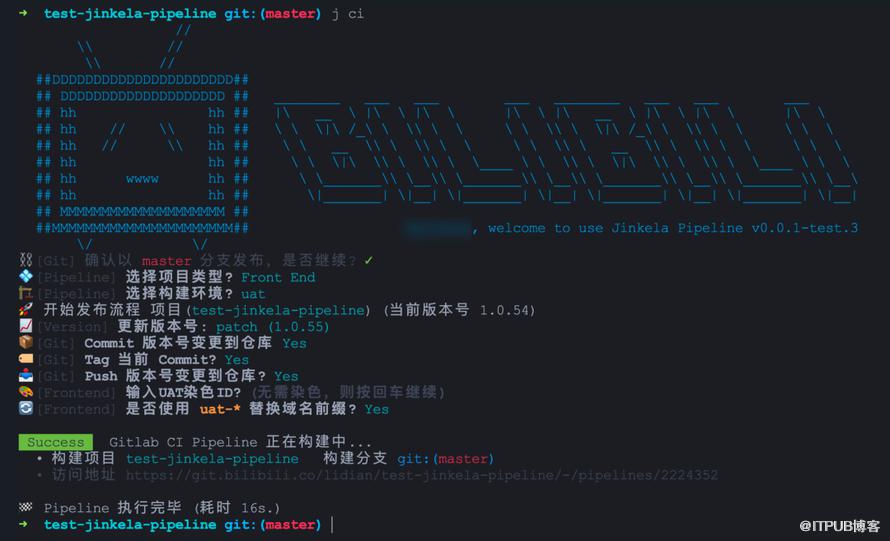
CI脚本,需要维护 实际的执行内容 + 触发执行的规则
Runner + 镜像 + 预载相关构建工具
拼接流水线触发时需要的参数
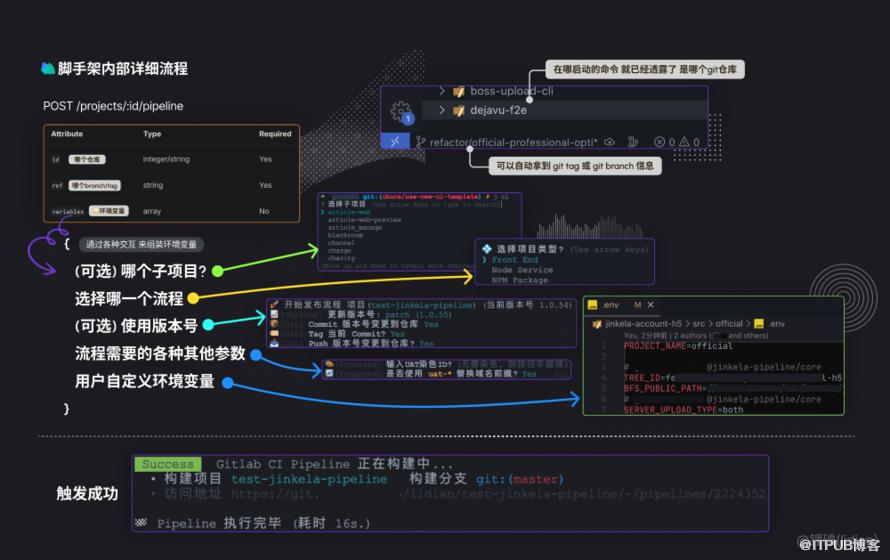
CLI 本质上就是一个 环境变量 收集器,命令行交互的 最终目的就是为了 拼凑流水线触发的必要参数。
命令执行时,当前所在目录即为 Git 仓库,结合 DotENV 文件读取,可以替用户减少大量重复字段的填写。其余字段才需要通过命令行交互获取。
CLI 内置了常见报错的半自动处理办法,也内置了各种检查来保证正确的使用姿势。
CLI 还内置了 Version Bump、Gitlab Release 的逻辑,让“打版本号”的操作变得足够简单。
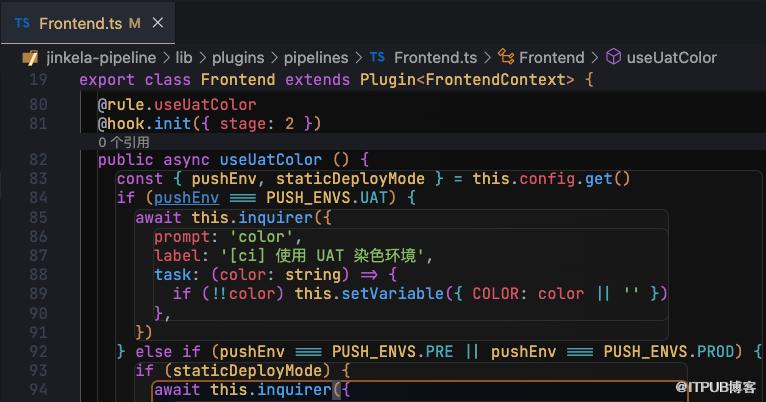
CLI 使用了 Tapable 开发插件机制,使用 TypeDI 依赖注入 为插件提供 Shell 执行、配置文件读取、MonoRepo 支持、日志收集、NPM、Gitlab、命令行交互 等能力,二次开发 inquirer.js 使其根据 Schema 约定来简化交互规则的开发。方便用户 开发 CLI 插件来定制流程交互。
为什么采取半自动的 CLI 的方式?
「维新派 vs 保守派」的使用习惯都能兼顾。
前端社区大量的开发工具也是类似的使用体验。

不需要额外打开浏览器页面,边开发边部署完全没有问题。
避免使用 Gitlab CI 其他的功能,引入不必要的复杂度。
更好地维护 CI 脚本
.gitlab-ci.yml 是 Gitlab CI 提供的流水线编排的 ProCode 方案,通过约定的格式 手写配置文件,即可自定义 CI 流水线。

这张图既是速查表,也是提高 Gitlab CI 脚本复用性的一种方法。
你可以使用 Gitlab CI 提供的「hidden job」特性和「代码复用」功能,
根据需要把每个 Job 的代码 拆分为「hidden job」「实体 job」两部分单独维护 (类似 abstract class 和 class 的关系),让代码尽可能保持精简、灵活。
MonoRepo 兼容
需要支持 MonoRepo 的原因是什么?
通过梳理B站前端应用的现状,不难发现:
仅从项目结构的维度上,就有大量的“分分合合”的不同解决方案 (根据数目从多到少排列↓)
PolyRepo
简单来说,就是一个仓库对应仅一个应用如果有新的应用出现就再单独建仓
Monolith
一种 Monolith 的方案: 一个仓库下存放一个大单体应用,内部包含多个“子应用”换而言之就是多个“子应用”复用同一个 package.json仅靠在执行 npm scripts 时使用不同的 命令参数 或 dotenv 文件来区分彼此, 来打出不同的产物包
MonoRepo
一个仓库下存放多个应用,使用各种社区第三方 monorepo tools例如使用 lernajs rushjs 等提供的新颖的 MonoRepo 方案,根据某种配置/约定 来自动识别 仓库下的 子应用
私有方案
例如 把所有应用的文件夹并排存放在仓库根目录中,实际开发时需要 cd 到具体某个二级目录开发例如 同一个仓库中 甚至可以同时存在多个 MonoRepo……
社区中同时存在各种 MonoRepo 方案
这里只枚举一些公司内部前端项目的常见工具
MonoRepo 是相当复杂的东西,下表透露的概念仅占不到 10%
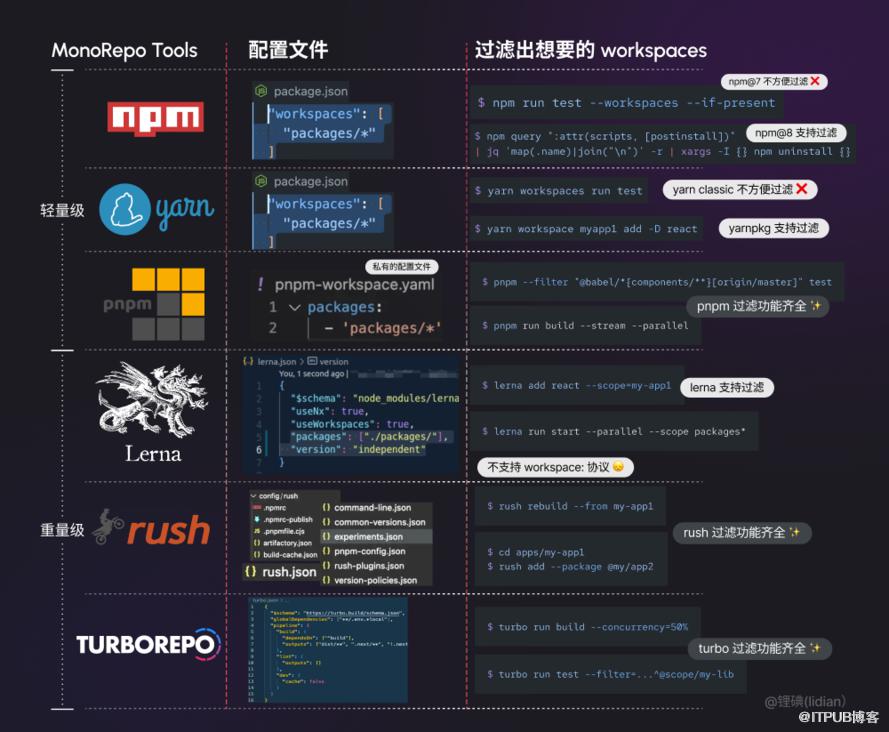
你看到了什么?
这意味着,想通过某种 “胶水层” 兼容上述所有方案的所有功能点是不太实际的。
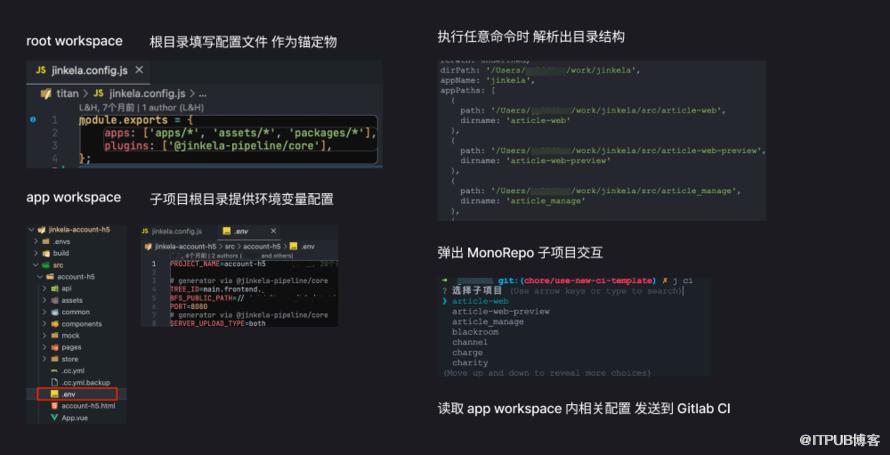
那么 Jinkela Pipeline 是怎么做的呢?
是从目录结构的角度切入的,这样做可以不侵入任何既有的解决方案。(换句话来说,也算是另辟蹊径 重复造轮子了)
优化
从效率、稳定性、用户体验、灵活性几个出发点考虑,各做了一些优化。
稳定性
充分利用好 lockfile 以保证构建环境一致性
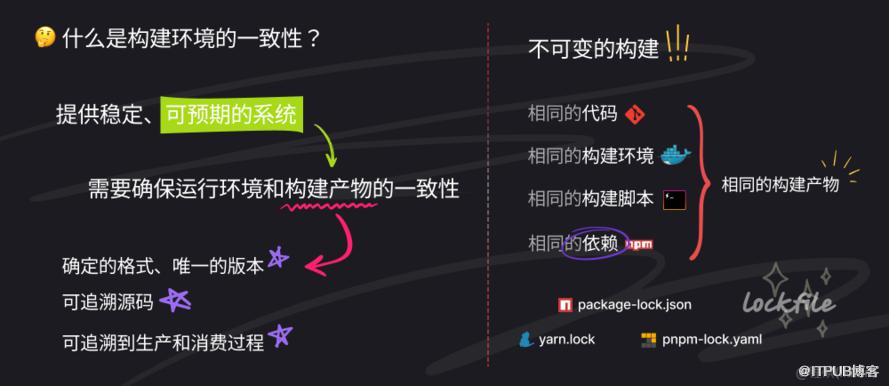
在构建制品的过程中,经常会遇到一些问题,例如一些库并没有很好的遵循版本号规范,仅仅升级了小版本号就导致其他项目无法构建。再例如,自己开发环境下构建正常,但一到多人协作就无法复现相同的构建结果。导致这些问题出现的原因 是「构建本身是可变的」。因此,我们需要通过不可变构建 使得构建产物与预期相符。
虽然 lockfile 不是解决一致性问题的唯一要点,但至少可以在 install/build 的时候 缩小问题规模,防止因为 「每次 install 了不一样的东西」 才导致的偶发性的构建差错,减少排查问题时的干扰。
此外,如果充分利用好 lockfile,CI 脚本中即可通过「匹配 lockfile 文件的类型」来决定「整条CI流水线使用哪种包管理器」。
效率
使用 Gitlab CI 提供的 DAG 功能,实现 并行Job
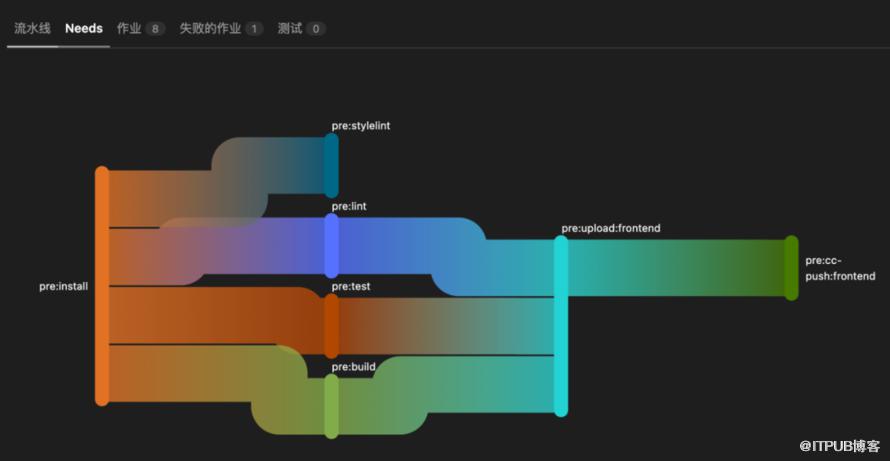
我们不应该粗暴地串行所有的任务,而是根据任务的重要性划分执行批次 各自执行,这是为了 缩短 关键路径(critical path),复用时间,让你更快达成你想要的结果。
包管理器 Store-dir 结合 CI 缓存

针对 不同的 包管理器 进行优化,舍弃 npm install,改用 npm ci,舍弃 yarn,改用 yarn --frozen-lockfile。
越大的大仓 越能感受到使用 npm ci 带来的性能提升,蚂蚁肉也是肉。
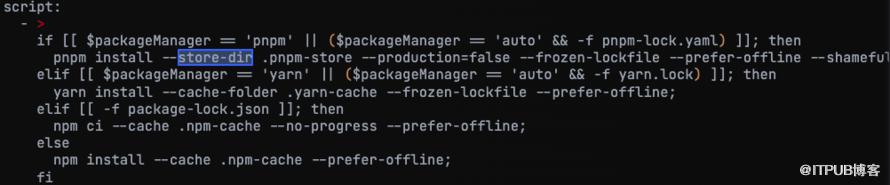
与此同时,可以按需使用 Gitlab CI 缓存,或结合 K8S Gitlab Runner 做更多优化。
细枝末节的优化
有很多改善性能的空间 可以被发现,很考验综合优化能力 ??
用户体验
对配置进行分门别类,优化不同项目的使用体验
满足不同规模的前端业务团队的需要,分为以下四个级别:
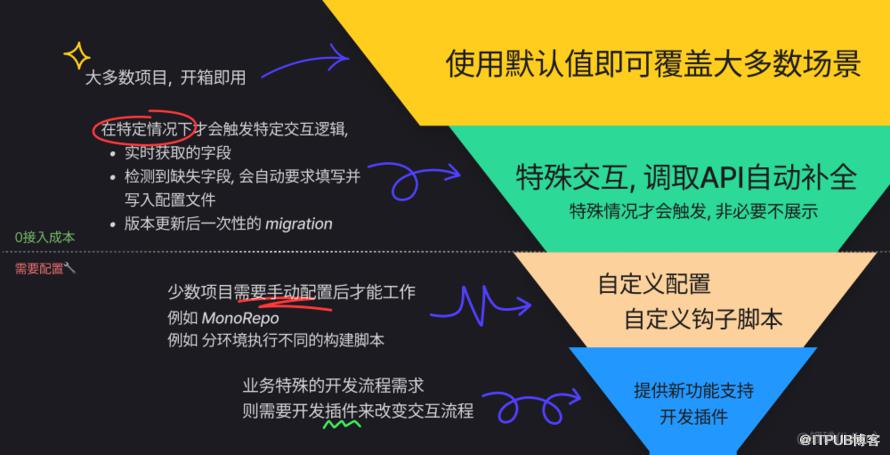
渐进式地解决问题
遇到现阶段难以打通的外部平台,我们至少可以先提供一个“Placeholder”……
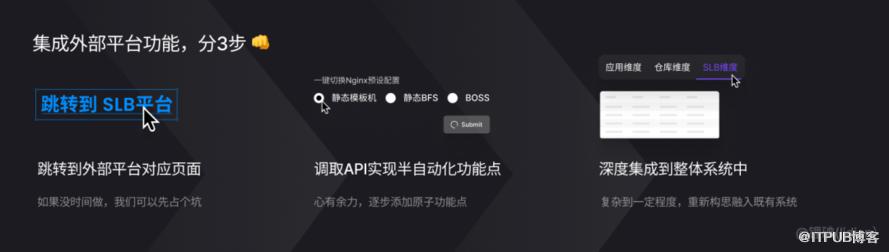
灵活性
部分项目拥有边缘的开发流程的需求,往往需要添加项目特有的逻辑/配置项,这些需求肯定不能纳入 通用 CI 脚本 来维护,那 Jinkela Pipeline 是如何解决的呢?
充分利用 Gitlab CI 的灵活性
Jinkela Pipeline 提供了整条链路上不同位置的多态性
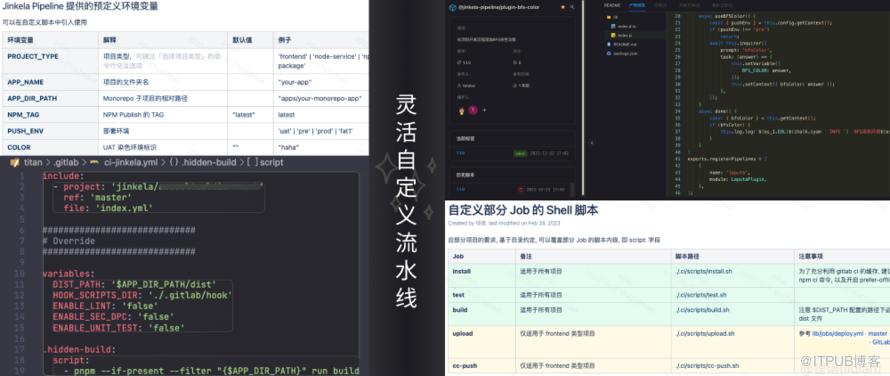
实际案例
实际案例
实际上大多数定制需求 都是 新增业务开发流程独有的 “变量”,结合简单的自定义脚本,来实现流程的灵活性。
这类需求高度雷同,我们需要通用化&简化 这种自定义能力。
这也是决定实现平台化的原因之一。??
平台化
没有平台时的难处
我们迫切需要解决这些核心体验问题。??
Dejavu 平台
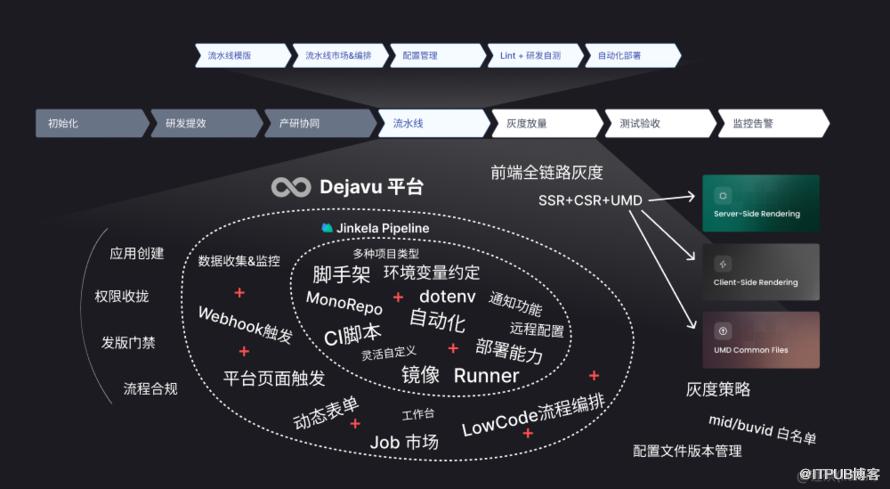
Dejavu 的流水线功能,基于原来的 Jinkela Pipeline 的各种功能点,扩展出了 更多独属于平台才能实现的功能:
LowCode 编辑器

CI 脚本 部分 从原来采用的 ProCode 方案,改为提供 LowCode 方案――CI脚本节点编辑器,
由于叠加了一层私有实现的 DSL,使得我们可以设计出可视化的界面、支持任意 CI 方案、还能做很多灵活的 hack。
繁琐的执行规则、串并联关系 交给用户打理,我们如今仅需维护 纯粹的执行内容相关逻辑 和 Job 的元信息,是不是变得优雅一些了呢?
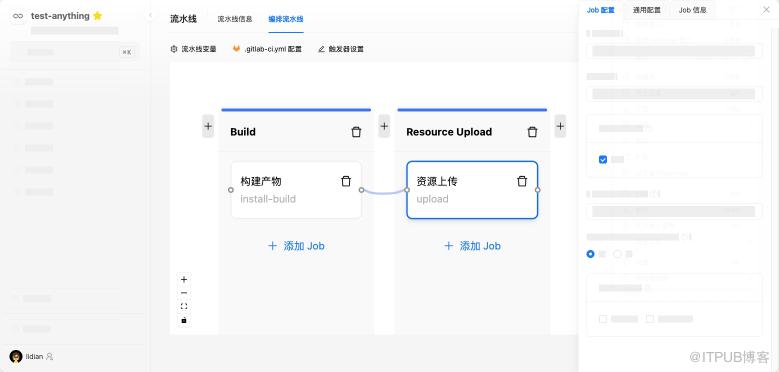
这是对 Gitlab CI 的一个全新的尝试,帮助我们获得这些特性:
总结
拥有一个这样的胶水层的收益是什么?
Roadmap
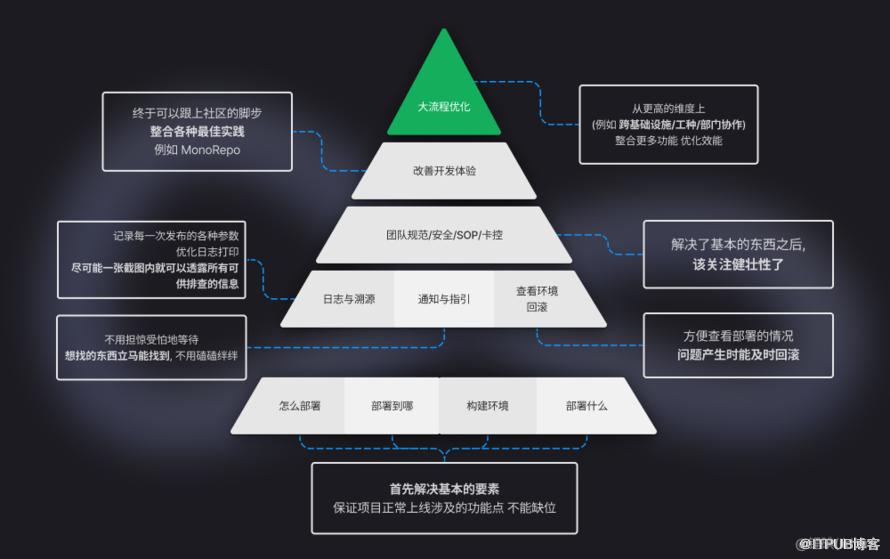
启示
DevOps 是我们有什么才能做什么
一个一个的细节得到了满足,才能释放开发者精力去投入有价值的事情
前端社区的性质决华宇注册定了 DevOps 需要 关注哪些特别的开发者体验?
展望
还能更快发起流水线
即使我们穷尽了无数种优化方法 (性能角度?流程优化角度?参数调优?),是不是就意味着我们没办法再优化了?
当然不是,我们还可以充分利用心理学上的一些小技巧。??
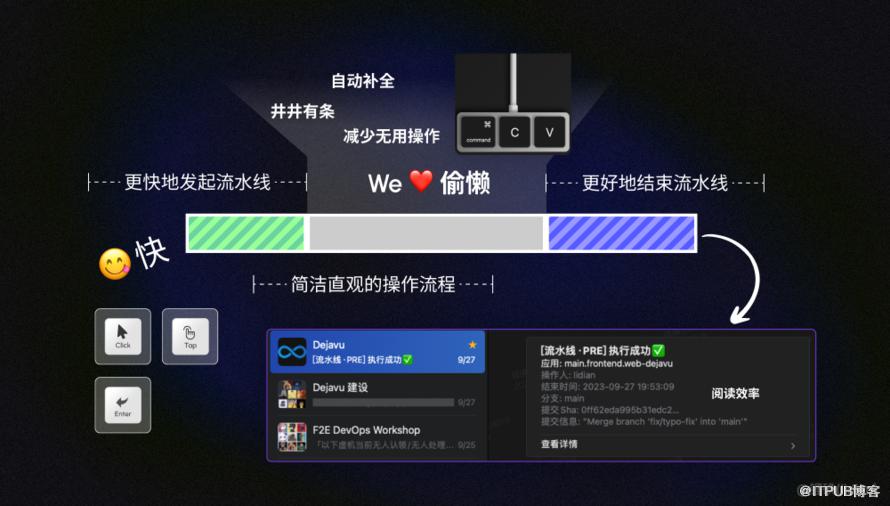
举例 格式塔定律
谁不喜欢井井有条的东西呢?
合理的结构化的摆放,可以用更少的字数,承载更多的信息量。
(还能暗示你,嗷 我们这个东西是相当高级的 安心)
举例 峰终定律
坐国正中心的电梯时,假如你按了[21楼],电梯在 19~20 楼的时候就提前告诉你快到了。诶,注意到尾声的这一点,你就感觉整个电梯流程是很快的。(事实上不然,你还是坐了 21层的电梯)
这是因为我们的感知是非线性的,我们对“决定性的时刻“印象最为深刻,掩盖了平淡过程的体验。
当然,我们仍需要探索更快的触发方式,以覆盖不同使用场景:
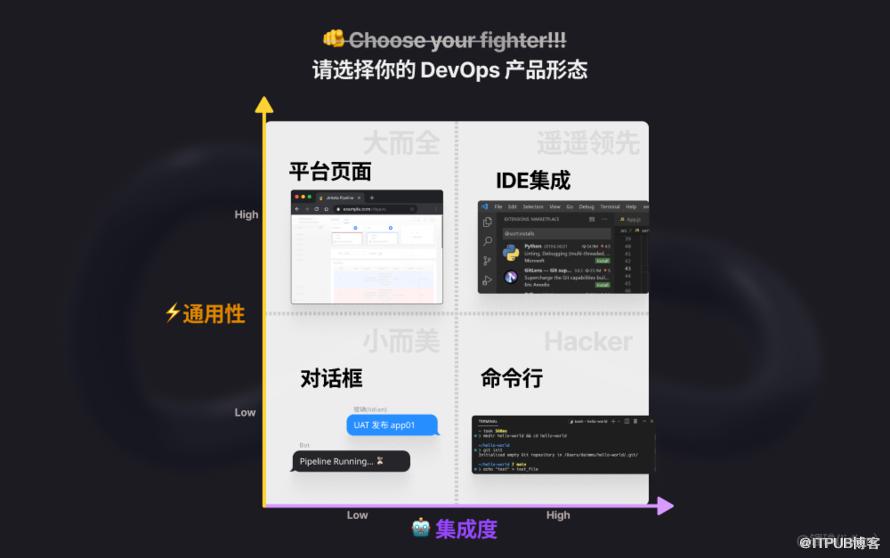
集成更多功能
DevOps 是个筐,啥都能往里装。
无非就是扩张自动化的边界,去“侵蚀”更多的协作流程,统统实现自动化。
(当然,也不是所有东西都适合自动化,是吧?)
 © 2023 华宇平台网 版权所有 蜀ICP备17051888号
© 2023 华宇平台网 版权所有 蜀ICP备17051888号